
O Apache Kafka é uma plataforma de streaming distribuída de código aberto usada para construir pipelines de dados e aplicativos em tempo real.
Criado pelo LinkedIn e posteriormente desenvolvido como um projeto de código aberto pela Apache Software Foundation, o Kafka é altamente escalável, durável e capaz de lidar com grandes volumes de dados em tempo real.
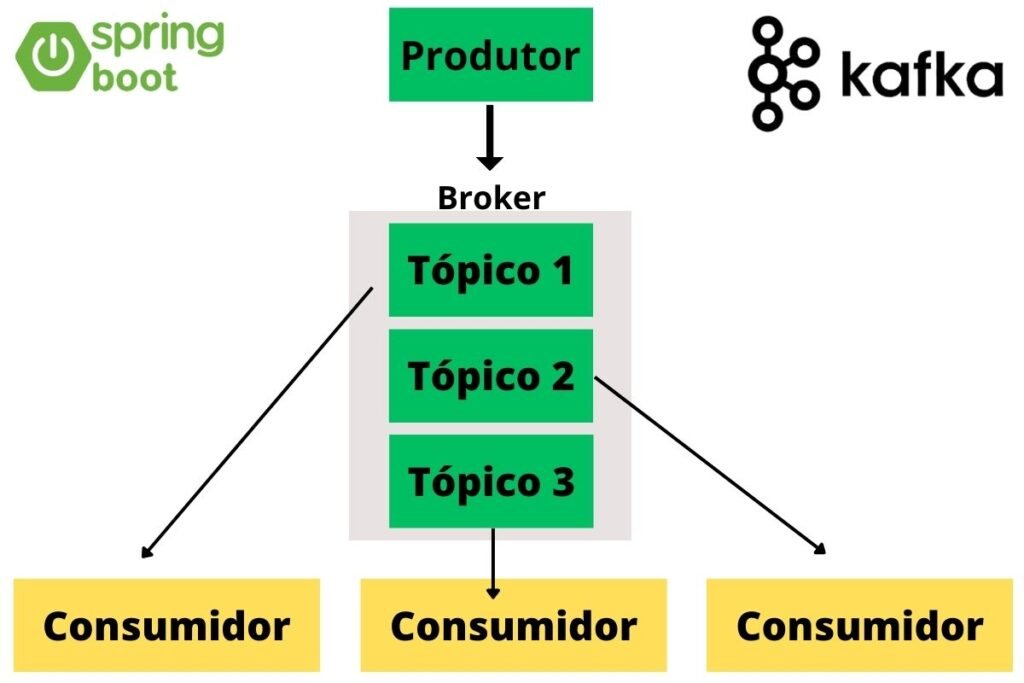
Arquitetura do Apache Kafka:
O Kafka é baseado em uma arquitetura de mensagens distribuídas. Ele consiste em alguns componentes principais:
- Productor (Producer): São os aplicativos ou sistemas que enviam dados para o Kafka. Eles publicam mensagens em tópicos específicos.
- Broker: É o núcleo do Kafka. Os Brokers armazenam os dados e são responsáveis pelo armazenamento, recebimento e replicação das mensagens.
- Tópico (Topic): É uma categoria específica para as mensagens. Os produtores publicam mensagens em tópicos e os consumidores as leem desses tópicos.
- Consumidor (Consumer): São os aplicativos ou sistemas que recebem e processam os dados do Kafka. Eles consomem mensagens de tópicos específicos.
Iniciando um Projeto Kafka com Spring Boot
Vamos iniciar as configurações em nosso projeto Spring Boot para integrar o Apache Kafka. Vamos começar um passo a passo de como configurar um ambiente de comunicação entre produtores e consumidores utilizando o Apache Kafka em conjunto com o Spring Boot:
Download ou Diretamente por um Container Docker
Se você não tem o Kafka intalado em sua máquina, pode conferir o site oficial do Apache Kafka, ou se preferir pode baixar uma imagem Docker para sua máquina, com os seguintes comandos e configurando da forma que preferir:
# Baixar a imagem do Apache Kafka docker pull confluentinc/cp-kafka # Criar e executar um contêiner Kafka docker run -d \ --name kafka \ -p 9092:9092 \ -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \ confluentinc/cp-kafka
Após esse procedimento já temos o Kafka rodando localmente, agora vamos iniciar as configurações em nosso projeto Spring Boot:
No arquivo pom.xml precisamos adicionar as dependências necessárias para prosseguirmos com o passo a passo:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>Bom, com a dependência adicionada, precisamos configurar nosso arquivo properties, no meu caso estou utilizando no formato Yaml:
spring:
kafka:
consumer:
bootstrap-servers: localhost:9092 # Endereço do servidor do Kafka
group-id: group_id # ID do grupo para o consumidor
auto-offset-reset: earliest # Configuração de reset do offset para o consumidor
producer:
bootstrap-servers: localhost:9092 # Endereço do servidor do KafkaTalvez algumas configurações não precisam necessariamente serem configuradas, mais resolvi deixar para não ter nenhum problema, agora precisamos iniciar nossas classes de configurações de Produtor e Consumidor:
package br.com.virandoprogramador.kafkaexemple
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class KafkaProducerService {
private static final String TOPIC = "virandoprogramador-topico";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String message) {
kafkaTemplate.send(TOPIC, message);
System.out.println("Mensagem enviada: " + message);
}
}A classe KafkaProducerService atua como uma interface entre a lógica de negócios da aplicação e o sistema de mensagens do Kafka, permitindo que a aplicação envie informações relevantes para o Kafka, onde podem ser consumidas por outros componentes, como o KafkaConsumerService, para processamento posterior.
Resumindo sobre o método
O método sendMessage na classe KafkaProducerService é usado para enviar uma mensagem para um tópico definido no Kafka. Este método geralmente recebe um parâmetro representando a mensagem a ser enviada. Dentro desse método, o KafkaTemplate é utilizado para publicar a mensagem no tópico correspondente no Kafka.
package br.com.virandoprogramador.kafkaexemple
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
private static final String TOPIC = "virandoprogramador-topico"; // Substitua pelo nome do seu tópico
@KafkaListener(topics = TOPIC, groupId = "group_id")
public void consume(String message) {
System.out.println("Mensagem recebida: " + message);
}
}Dentro da classe KafkaConsumerService, é comum encontrar o uso da anotação @KafkaListener. Essa anotação é uma funcionalidade fornecida pelo Spring Kafka que permite que um método específico dentro da classe atue como um consumidor do Kafka para um determinado tópico. O @KafkaListener especifica o tópico a ser ouvido e o grupo de consumidores associado a esse ouvinte.
O método anotado com @KafkaListener deve ter a lógica de processamento para as mensagens recebidas do tópico do broker. Quando uma mensagem é publicada no tópico correspondente, o Kafka chama automaticamente o método marcado com @KafkaListener, passando a mensagem recebida como parâmetro para ser processada conforme a necessidade da aplicação.
Agora precisamos configurar a classe de Config do Kafka, para dizer ao Spring como as mensagens deve ser serializadas:
package br.com.virandoprogramador.kafkaexemple
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.support.serializer.JsonSerializer;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(org.apache.kafka.clients.producer.ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(org.apache.kafka.clients.producer.ProducerConfig.
KEY_SERIALIZER_CLASS_CONFIG, org.apache.kafka.common.serialization.StringSerializer.class);
config.put(org.apache.kafka.clients.producer.ProducerConfig.
VALUE_SERIALIZER_CLASS_CONFIG, org.apache.kafka.common.serialization.StringSerializer.class);
return new DefaultKafkaProducerFactory<>(config);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Normalmente, essa classe também é usada para definir configurações específicas do Kafka, como o endereço dos servidores do Kafka, serializadores para chaves e valores das mensagens, e outras configurações relacionadas à produção e consumo de mensagens.
Essa configuração permite ao aplicativo criar um KafkaTemplate devidamente configurado, que pode ser injetado em outras partes do código para enviar mensagens para tópicos do Kafka de maneira eficiente e confiável.
Bom, finalizamos nossas configurações, no geral os projetos feitos com Spring Boot utilizam essas configurações bases, para todo projeto inicial você irá utilizar configurações como estas, pois é a base do funcionamento de um projeto com Mensagerias Pub/Sub.
Conclusão sobre o Apache Kafka:
O Kafka oferece uma arquitetura sólida de mensagens distribuídas, composta por produtores, consumidores e tópicos, permitindo a troca de dados de maneira confiável e eficiente.
Sua flexibilidade e capacidade de processar fluxos de dados em tempo real o tornam ideal para uma variedade de casos de uso, desde análises em tempo real até integração de sistemas distribuídos e processamento de grandes volumes de dados.
Porém ele não é o único, existe outros como: RabbitMQ, IBM MQ, SQS da AWS, entre outros.
Em resumo, o Apache Kafka é uma ferramenta poderosa para lidar com fluxos de dados em tempo real, mas sua implementação eficaz requer uma compreensão aprofundada de seus conceitos e funcionalidades.
Se usado adequadamente, Este Broker pode ser um ativo valioso para uma variedade de aplicações que demandam processamento de dados em tempo real, integração de sistemas distribuídos e escalabilidade.


